KI intuitiver durch Brain-Computer Interfaces trainieren
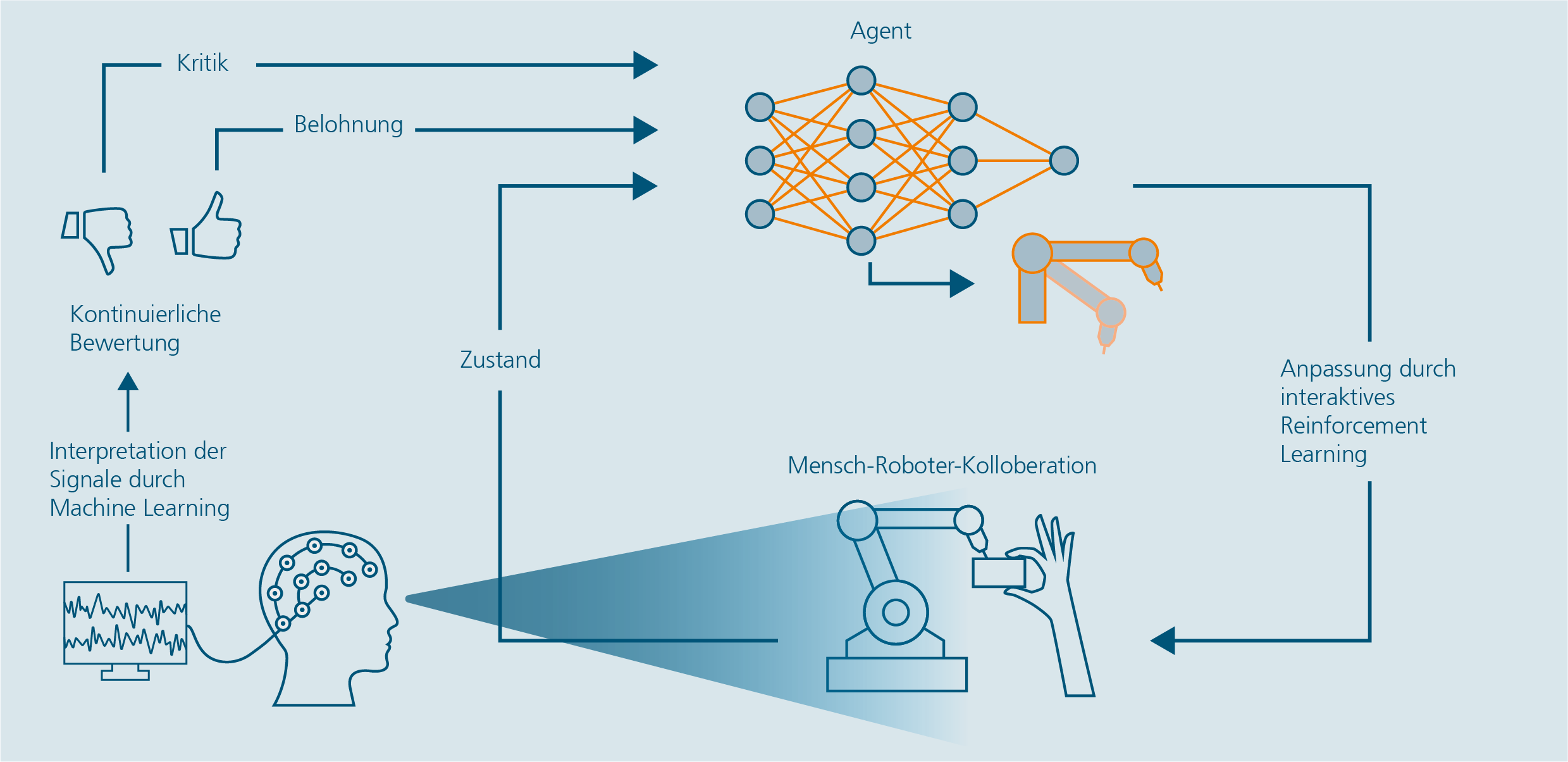
Interaktives Reinforcement Learning für autonom handelnde KI-Systeme – Lernen aus menschlichen perzeptiven Reaktionen durch ein Brain-Computer Interface.
Herausforderung
Die Sichtprüfung ist eine gängige Methode der Qualitätssicherung in industriellen Prozessen. Hierbei handelt es sich um eine meist visuelle Kontrolle eines Produktes auf Fehler – wie Kratzer, Schmutzablagerungen oder Montagefehler. Da Sichtprüfungen hauptsächlich durch Menschen ausgeführt werden, unterliegen sie einem schlechten Wirkungsgrad. Ursächlich hierfür sind Konzentrationsschwankungen, Ermüdung oder Ablenkung. Zudem wirken sich monotone Prüfprozesse nachteilig auf das Befinden und Gesundheit der Prüfenden aus. Gerade bei nicht komplett automatisierbaren Qualitätskontrollen gilt es zu klären, wie der prüfende Mensch unterstützt werden kann.
Methodik
Ein vielversprechender Ansatz ist das »Lernen von menschlichem Feedback«. Hierbei kann der Mensch während des Lernprozesses Rückmeldung an den Agenten geben. Unser Projekt zielt darauf ab, ein neuartiges interaktives RL-Verfahren zu entwickeln, das menschliches Feedback über ein Brain-Computer Interface (BCI) direkt ableitet, basierend auf implizit gemessenen Hirnsignalen, wie dem sogenannten Fehlersignal im Gehirn (error-related potential, ErrP). Das ErrP tritt immer dann auf, wenn Menschen etwas fehlerhaftes oder inkongruentes wahrnehmen und lässt sich über die Elektroenzephalographie (EEG) messen. Dies ermöglicht es dem Menschen, Fehler des Roboteragenten schnell und direkt zu erkennen und weiterzugeben, ohne zusätzlichen Aufwand.
Ergebnis
In einer ersten Studie verglichen wir verschiedene EEG-Geräte (gel-basierte und trocken-basierte Elektroden) und maschinelle Lernmethoden, um zu beurteilen, wie gut sie zwischen optimalen und suboptimalen Verhaltensweisen von Robotern (Klassifikation des gemessenen ErrP im EEG der Person) unterscheiden können. Dabei wurden klassische Feature Engineering basierte Ansätze versus Klassifikationen auf der Grundlage der Riemannschen Geometrie und Convolutional Neural Network (CNN) verglichen. Unsere Ergebnisse zeigten, dass das CNN-basierte Modell am besten abschnitt, unabhängig von der Anzahl der Sensoren oder dem Einsatz von Gel. Auch die Anzahl der Sensoren spielte keine entscheidende Rolle für die Genauigkeit der Ergebnisse. In einer zweiten empirischen Machbarkeitsstudie haben wir einen Proof-of-Concept Demonstrator in einer physikalisch realistischen Simulationsumgebungen erprobt. Dazu verglichen wir den neuartigen, impliziten BCI-gesteuerten RL-Trainingsansatz mit explizitem menschlichem Feedback. Unsere Ergebnisse zeigen eine signifikante Beschleunigung und Verbesserung der Lernleistung durch den Einsatz von BCIs, verglichen mit traditionellen Methoden, die auf spärlichen Belohnungen (ohne menschliches Feedback) basieren. Weiterhin zeigen unsere Ergebnisse, dass die Leistung unseres BCI-basierten Ansatzes sogar vergleichbar mit derjenigen ist, die durch herkömmliches explizites Feedback erreicht wurde. Unsere Methode demonstriert den Mehrwert der Kombination von BCI- und KI-Technologien für ein intuitiveres und effizienteres Robotertraining, was nicht nur die Trainingszeiten verkürzen, sondern auch die Entwicklung von adaptiven und empathischen Maschinen beschleunigen könnte. Dies ist besonders wertvoll in Szenarien, in denen explizites, kognitiv anspruchsvolles Feedback nicht verfügbar ist.